This project focuses on detecting anomalies in battery health using data from NASA. The primary goal is to identify potential issues in battery performance to enhance maintenance strategies and ensure reliability.




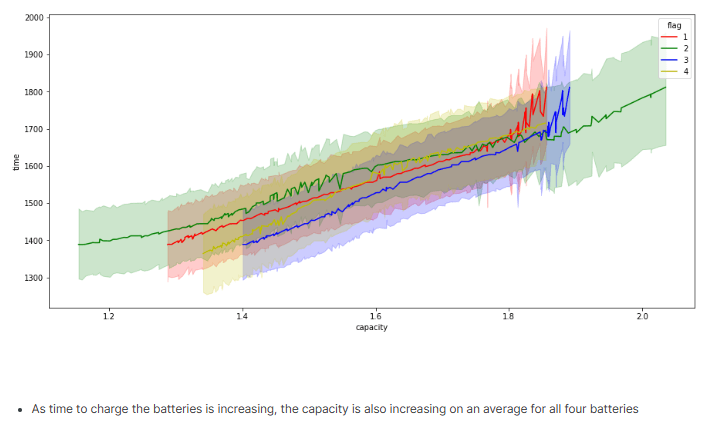




I have tried 5 methods for anamoly detection:
Isolation Forest >> Local Outlier Factor (LOF) > DBSCAN (density based) > Elliptical Envelope >> IQR based
